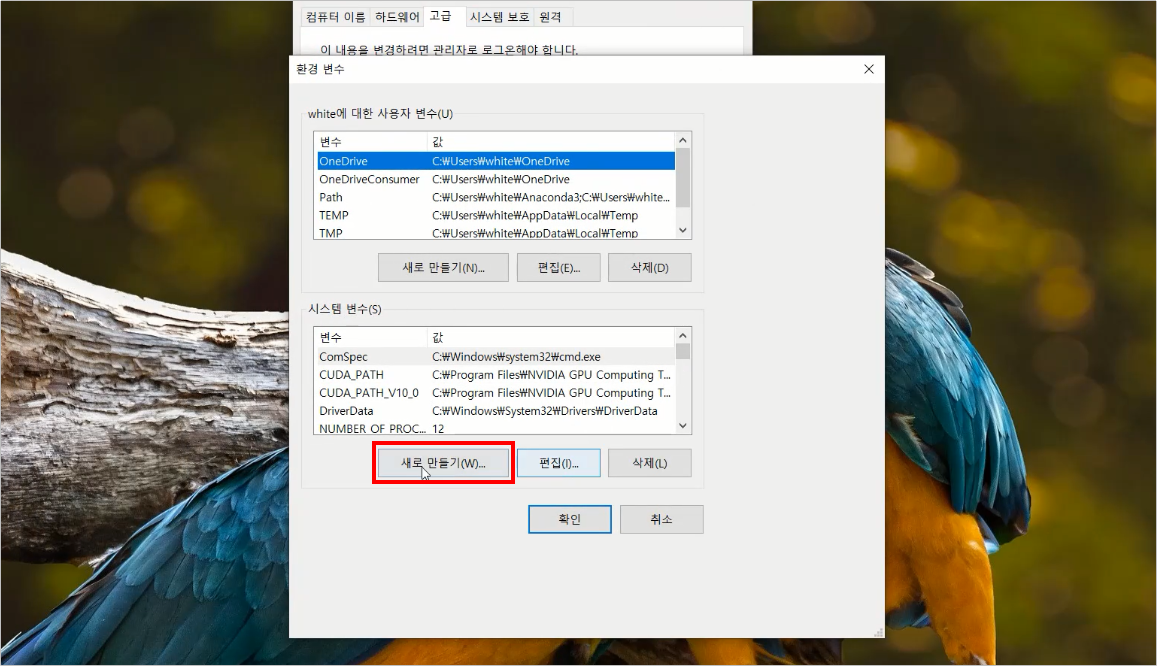
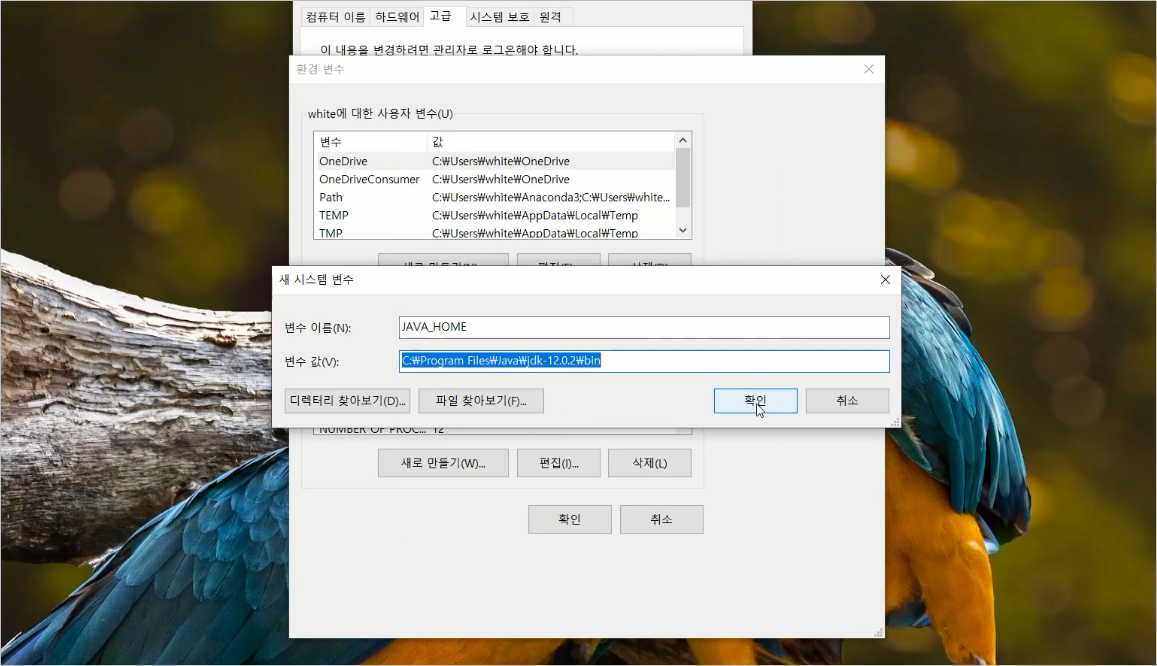
[Python/Anaconda] Apply + Lambda + List comprehension을 이용한 강력한 코딩 꿀팁!
딥러닝 공부/자연어처리 2019. 8. 9. 23:01
안녕하세요. 은공지능 공작소의 파이찬입니다.
오늘은 자연어처리 강력한 코딩 팁을 들고 왔습니다.
apply, lambda, python comprehension을 이용한 데이터 EDA 방법입니다.
이 3가지 조합으로 정말 많은 정보들을 뽑아낼 수 있습니다.
저도 이 3가지 코딩법은 각각 알고 있었지만, 이것을 조합해서 쓸 때 더욱 강력하다는 것을 알았고,
또 몸에 체득하는 것이 중요하다는 것을 알았습니다.
여러분들도 실전 코딩에서 유용하게 사용하실 수 있길 바랍니다.
그럼 시작해보겠습니다.
1. 데이터 생성해주기

데이터는 성경 데이터를 가져왔습니다. 마태복음 11장입니다.
"무거운 짐 진 자들아 다 내게로 오라 내가 너희를 쉬게 하리라"
라는 구절로 유명한 챕터입니다. 마음이 평온해지는 구절이죠. ^^
데이터 생성하는 부분은 크게 중요하지 않으니,
그냥 아래 코드를 복붙하셔서 진행하시면 됩니다.
data = '''After Jesus had finished instructing his twelve disciples, he went on from there to teach and preach in the towns of Galilee.
When John heard in prison what Christ was doing, he sent his disciples
to ask him, "Are you the one who was to come, or should we expect someone else?"
Jesus replied, "Go back and report to John what you hear and see:
The blind receive sight, the lame walk, those who have leprosyare cured, the deaf hear, the dead are raised, and the good news is preached to the poor.
Blessed is the man who does not fall away on account of me."
As John's disciples were leaving, Jesus began to speak to the crowd about John: "What did you go out into the desert to see? A reed swayed by the wind?
If not, what did you go out to see? A man dressed in fine clothes? No, those who wear fine clothes are in kings' palaces.
Then what did you go out to see? A prophet? Yes, I tell you, and more than a prophet.
This is the one about whom it is written: " 'I will send my messenger ahead of you, who will prepare your way before you.'
I tell you the truth: Among those born of women there has not risen anyone greater than John the Baptist; yet he who is least in the kingdom of heaven is greater than he.
From the days of John the Baptist until now, the kingdom of heaven has been forcefully advancing, and forceful men lay hold of it.
For all the Prophets and the Law prophesied until John.
And if you are willing to accept it, he is the Elijah who was to come.
He who has ears, let him hear.
"To what can I compare this generation? They are like children sitting in the marketplaces and calling out to others:
" 'We played the flute for you, and you did not dance; we sang a dirge and you did not mourn.'
For John came neither eating nor drinking, and they say, 'He has a demon.'
The Son of Man came eating and drinking, and they say, 'Here is a glutton and a drunkard, a friend of tax collectors and "sinners." ' But wisdom is proved right by her actions."
Then Jesus began to denounce the cities in which most of his miracles had been performed, because they did not repent.
"Woe to you, Korazin! Woe to you, Bethsaida! If the miracles that were performed in you had been performed in Tyre and Sidon, they would have repented long ago in sackcloth and ashes.
But I tell you, it will be more bearable for Tyre and Sidon on the day of judgment than for you.
And you, Capernaum, will you be lifted up to the skies? No, you will go down to the depths. If the miracles that were performed in you had been performed in Sodom, it would have remained to this day.
But I tell you that it will be more bearable for Sodom on the day of judgment than for you."
At that time Jesus said, "I praise you, Father, Lord of heaven and earth, because you have hidden these things from the wise and learned, and revealed them to little children.
Yes, Father, for this was your good pleasure.
"All things have been committed to me by my Father. No one knows the Son except the Father, and no one knows the Father except the Son and those to whom the Son chooses to reveal him.
"Come to me, all you who are weary and burdened, and I will give you rest.
Take my yoke upon you and learn from me, for I am gentle and humble in hear t, and you will find rest for your souls.
For my yoke is easy and my burden is light."'''data_dict = {}
data_dict['verse'] = []
for row in [x for x in data.split('\n')]:
data_dict['verse'].append(row)
bible_data = pd.DataFrame.from_dict(data_dict)
# bible_data이렇게 하여 마태복음 11장을 가지고 데이터 프레임을 만들어 보았습니다.
다음으로 Apply 함수에 대해 이해해보는 시간을 가지겠습니다.
2. Apply 함수 이해하기
Apply 함수는 컬럼 단위로 적용되는 함수입니다.
즉, 행열 중 열을 기준으로 다양한 함수를 적용합니다.
적용되는 함수는 기본함수부터 사용자가 정의한 함수까지 다양합니다.
물론 람다(lambda)도 쓰일 수가 있고요.
그럼 길이를 구하는 len 함수부터 적용해서 이해를 해보겠습니다.
bible_data['verse'].apply(len)output:
0 125
1 70
2 80
...
27 74
28 116
29 44
Name: verse, dtype: int64이렇게 하면 verse 컬럼에 있는 모든 데이터에 len 함수가 적용되어 그 값이 출력이 됩니다.
한 번 type같은 함수들도 직접 적용해보시길 바랍니다.
이렇게 len(input), type(input) 형식으로 사용되는 함수들은 바로 적용을 시킬 수가 있습니다.
이런 함수들은 괄호 안에 인자를 넣어서 작동하는 기본 함수들입니다.
하지만 이러한 기본함수들 이외에도 점( . )을 이용해 쓰는 함수들도 있습니다.
apply 함수만 해도 점( . )을 이용해 쓰는 함수이고,
list.append 등도 이러한 방식으로 사용이 됩니다.
이런 함수들은 lambda를 통해 적용을 할 수 있습니다.
바로 아래에서 자세히 다루어 보겠습니다.
3. Lambda 함수 이해하기
bible_data['verse'][0] output:
'After Jesus had finished instructing his twelve disciples, he went on from there to teach and preach in the towns of Galilee.'위와 같이 마태복음 11장 1절을 살펴보겠습니다.
첫 글자가 After~ 와 같이 대문자로 시작하는 것을 확인할 수 있습니다.
하지만 모든 절(verse)이 다 대문자로 시작하는 것은 아닙니다.
그래서 저희는 lambda를 이용해서,
이 첫 글자가 대문자인지 검사하는 코드를 작성해 보겠습니다.
여기에는 2가지 방법이 있습니다.
① 직접 사용자 정의 함수를 만든다.
② 람다 구문을 이용한다.
물론 제가 강조드리고 싶은 것은 ②번이지만, ①번부터 차근차근 다 살펴보도록 하겠습니다.
def IsUpper(input):
return input[0].isupper()
bible_data['verse'].apply(IsUpper)output:
0 True
1 True
2 False
...
27 False
28 True
29 True
Name: verse, dtype: bool위와 같이 사용자 정의 함수 + apply 함수를 이용하여,
첫글자가 대문자인지를 검사할 수 있습니다.
하지만 그것보다 더 간단한 방법이 있는데,
그것이 바로 lambda 구문의 활용입니다.
bible_data['verse'].apply(lambda x : x[0].isupper())output:
0 True
1 True
2 False
...
27 False
28 True
29 True
Name: verse, dtype: bool이런 식으로 즉석에서 사용자 정의 함수를 만드는 것이 바로 lambda 구문입니다.
아까와 동일한 결과를 내놓지만 코드는 더 깔끔하죠!
이런 것들이 몸에 체득이 되면, 코딩 실무에서 매우 강력한 무기가 될 수 있고
고수의 느낌도 슬슬 풍길 수 있습니다.
여기에다가 list comprehension을 더해주면 더욱 완벽해집니다.
4. List comprehension 이해하기
List comprehension... 이름만 들으면 참 아리송합니다.
리스트는 파이썬의 리스트 데이터 타입을 말하는 것인데,
컴프리헨션의 의미와 구문 사용법이 잘 매칭이 되질 않습니다.
굳이 짜맞추자면 "고도의 이해력을 가진 사람만이 쓸 수 있는 코딩구문"(???)
네 개소리인 것 같습니다...ㅋㅋㅋ
그냥 컴프리헨션이라는 코딩 문법이 있고, 사용법을 숙지하고 가시면 됩니다.
이번에는 각 row 마다 대문자의 개수를 세주는 상황을 가정하겠습니다.
마태복음 11장은 총 30절이 있으니, 30개의 숫자를 가진 컬럼이 출력되는 방식입니다.
가장 기본적은 Comprehension부터 살펴보겠습니다.
[i for i in bible_data['verse']]output:
['After Jesus had finished instructing his twelve disciples, he went on from there to teach and preach in the towns of Galilee.',
'When John heard in prison what Christ was doing, he sent his disciples',
'to ask him, "Are you the one who was to come, or should we expect someone else?"',
...
'"Come to me, all you who are weary and burdened, and I will give you rest.',
'Take my yoke upon you and learn from me, for I am gentle and humble in heart, and you will find rest for your souls.',
'For my yoke is easy and my burden is light."']가장 기본적인 List comprehension의 구문입니다.
이런 식으로 Comprehension은 리스트 대괄호로 감싸주는 것이 기본입니다.

일반적인 for 반복문은 많이 보셨을 것입니다.
list comprehension은 간단한 코딩을 위해 실행문을 for문 앞으로 가져오는 것입니다.
위의 그림을 보면 이해가 쉬우실 겁니다.
달라지는 점은 실행문이 앞으로 온다는 것, 그리고 대괄호로 감싸주는 것뿐입니다.
[len(i) for i in bible_data['verse']]output:
[125,
70,
80,
...
74,
116,
44]좀 더 이해를 돕기 위해, i 에 len() 함수를 씌워보았습니다.
이런 식으로 함수를 씌워주면, 모든 데이터가 len 함수를 거쳐서 나오게 됩니다.
이것이 바로 for문을 간단하게 코딩할 수 있는 list comprehension입니다.
5. 종합 연습 (Apply, Lambda, List comprehension 모두 사용)
지금까지 Apply, Lambda, List comprehension까지 모두 다루어보았습니다.
이제는 이 3가지 무기들을 조합해, 강력한 무기를 사용해볼 때입니다.
이번에는 각 절(verse) 마다 몇 개의 대문자가 있는지
출력해보는 상황을 가정하겠습니다.
코딩 논리 흐름은 다음과 같습니다.
apply로 문장에 접근 -> 문자 별로 쪼개고 대문자인 것을 True/False로 출력 -> np.sum
bible_data['verse'].apply(lambda x: [i for i in x]) # lambda x는 in 뒤에 들어갑니다.
bible_data['verse'].apply(lambda x: [i.isupper() for i in x]) # for앞이 실행문인것 기억
bible_data['verse'].apply(lambda x: np.sum([i.isupper() for i in x])) # np.sum 위치 주목output:
0 3
1 3
2 1
...
27 2
28 2
29 1
Name: verse, dtype: int64한 줄, 한 줄 실행해보시면 이해가 빠르실 것입니다.
output은 마지막 줄 결과만 담았습니다.
위와 같은 방식으로 얼마든지 여러 줄의 코딩을 간단하게 만들 수 있습니다.
모두 몸과 마음에 잘 익혀두어 고수의 길을 가시길 바랍니다!
오늘 포스팅은 여기까지 하겠습니다. 감사합니다.
반응형
'딥러닝 공부 > 자연어처리' 카테고리의 다른 글

pychan
딥러닝에 관련된 시행착오, 사소하지만 중요한 것들, 가능한 모든 여정을 담았습니다.