



안녕하세요! 은공지능 공작소의 파이찬입니다.
오늘은 파이썬으로 IMDB 영화데이터를 다운받고 전처리해보겠습니다.
전처리 작업은 자연어 처리를 위한 라벨링까지 진행합니다.
Ratings and Reviews for New Movies and TV Shows - IMDb
IMDb is the world's most popular and authoritative source for movie, TV and celebrity content. Find ratings and reviews for the newest movie and TV shows.
www.imdb.com
위의 사이트가 바로 IMDb 영화 리뷰 사이트입니다.
시간 되시는 분들은 접속하셔서 쓱~ 한번 둘러보시는 것도 좋습니다.
저희는 웹크롤링을 하면 좋겠지만... 스탠퍼드 대학교에서 데이터를 모아 둔 것이 있으므로,
이 데이터를 다운받아서 바로 사용하도록 하겠습니다 ^^
1. 데이터 다운받기
import os, re
import pandas as pd
import tensorflow as tf
from tensorflow.keras import utils
dataset = tf.keras.utils.get_file(
fname='imdb.tar.gz', # 다운받은 압축파일의 이름
origin = "http://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz", # 링크주소
extract = True) # 압축 해제 여부우선 import 명령어를 사용해서 필요한 모듈을 다운받아 줍니다.
데이터셋을 다운받는 방법은 위와 같습니다.
자세한 설명은 코드 주석으로 대체하겠습니다.
Keras의 utils 함수는 웹 상의 데이터를 쉽게 다운로드 할 수 있도록 지원해줍니다.
링크 주소는 오타가 나기 쉬우니, 제 코드 복붙하시길 바랍니다.
(오른쪽 클릭하시고 복붙해가세요~! 오른쪽마우스 클릭방지 안 걸어 놨습니다 ㅎㅎ)
basic_dir = os.path.dirname(dataset)
print(basic_dir)output:
C:\Users\white\.keras\datasets이제 데이터를 다운받았으니, 데이터가 어느 경로에 있는지 확인이 필요합니다.
os.path.dirname 함수를 사용하면, 데이터의 경로를 확인할 수 있습니다.
한 번 직접 윈도우 탐색기를 통해서 폴더 구조를 살펴봅시다.

경로를 따라 직접 폴더에 들어가보시면, 위의 화면같은 창이 뜰 것입니다.
크게는 Train data와 Test data로 나뉘어져 있고,
그 안에는 Positive 리뷰와 negative 리뷰가 있습니다.
각각의 앞글자를 따서 폴더 이름은 pos, neg라고 되어 있을 것입니다.

test 폴더의 neg 폴더까지 들어가보았습니다. 여기서 txt 파일을 하나 열어봅시다.
저런 식으로 한 텍스트 파일 안에는 리뷰가 여러 문장으로 존재합니다.
그러니 코딩을 할 때, 크게 4 종류의 파일에 접근을 해야 하는 것입니다.
(train_pos, train_neg, test_pos, test_neg)
이러한 구조를 기억하면서 다음으로 넘어가겠습니다.
2. txt 파일을 가져와 데이터 담기
변수 리스트:
basic_dir = 'C:\Users\white\.keras\datasets'os.path.join(basic_dir, 'aclImdb')output:
'C:\\Users\\white\\.keras\\datasets\\aclImdb'basic_dir 변수에는 dataset 폴더까지의 경로가 담겨 있습니다.
만일 여기서 한단계 하위 폴더에 접근하고 싶다면, os.path.join 함수를 쓰시면 됩니다.
os.path.join(basic_dir, 'aclImdb') 이라고 입력하시면,
그 데이터셋보다 한 단계 아래인 폴더에까지 접근이 가능합니다.
이렇게 os.path.join 함수는 디렉터리 경로를 조인해주는 역할을 합니다.
path_train_pos = os.path.join(basic_dir, 'aclImdb', 'train', 'pos')
path_train_posoutput:
'C:\\Users\\white\\.keras\\datasets\\aclImdb\\train\\pos'이제 위와 같이 써주면, 텍스트파일이 있는 경로까지 접근이 가능합니다.
이 경로를 path_train_pos에 저장하도록 하겠습니다.
그렇다면 이제 각각의 텍스트 파일에 접근해야 하는 과제가 남았습니다.
이럴 때 사용하기 딱 좋은 함수가 하나 있습니다.
os.listdir(path_train_pos)output:
['0_9.txt',
'10000_8.txt',
...]바로 os.listdir 함수입니다.
이 함수는 인자 경로에 있는 파일들을 리스트에 담아서 출력을 해줍니다.
그렇지 않으면 일일이 12,500개의 txt 파일을 손코딩 해야 할 수밖에요..
for i in os.listdir(path_train_pos):
path = os.path.join(path_train_pos, i)
print(path)output:
C:\Users\white\.keras\datasets\aclImdb\train\pos\0_9.txt
C:\Users\white\.keras\datasets\aclImdb\train\pos\10000_8.txt
C:\Users\white\.keras\datasets\aclImdb\train\pos\10001_10.txt
...이제 for 반복문으로 각각의 텍스트 파일의 경로들을 만들어 줍니다.
위와 같이 os.path.join을 쓰면, path_train_pos 경로의 모든 txt 파일경로를 출력할 수 있습니다.
for i in os.listdir(path_train_pos):
path = os.path.join(path_train_pos, i)
# print(path)
rst = open(path, "r", encoding="UTF-8").read()
print(rst+ '\n\n')이제 각각의 txt 파일에 접근했으니, 해당 파일들을 읽어보는 작업을 해보겠습니다.
파일 읽는 법은 open().read()를 써주면 됩니다.
open 함수 안에는 ① 경로명, ② 모드, ③ 인코딩이 인자로 들어갑니다.
저는 open(path, "r", encoding = 'UTF-8') 이라고 했습니다.
코드의 의미는, ①경로명은 path 변수에 담긴 것으로 하겠다.
② 모드는 "r" 즉, reading 모드를 적용하겠다. (그밖에 w, a 모드가 있습니다.)
③ 인코딩은 UTF-8을 적용하겠다. 정도로 봐주시면 됩니다.
특히 인코딩 부분을 명시하지 않을 경우, 오류가 발생할 수 있으니
이 점 유의해주시길 바랍니다.

출력 결과는 위와 같습니다. print 문에 '\n\n'을 넣어서, 각각의 txt 파일을 구분했습니다.
출력 결과를 보시면 중간에 2칸의 공백줄이 추가된 것을 보실 수 있습니다.
이제 이러한 rst 결과물들을 딕셔너리에 담아보는 작업을 해보겠습니다.
# 먼저 데이터라는 딕셔너리를 하나 생성해줍니다.
data = {}
# 그리고 그 안에, txt라는 키를 가진 리스트를 하나 만들어 줄게요.
data['txt'] = []
for i in os.listdir(path_train_pos):
path = os.path.join(path_train_pos, i)
rst = open(path, "r", encoding="UTF-8").read()
data['txt'].append(rst)
# list.append()는 리스트에 데이터를 계속 추가해줍니다.먼저 data라는 딕셔너리를 하나 만들어주고,
그 안에 'txt'라는 키를 가진 리스트를 생성해 줍니다.
그리고 for 반복문에서 계속 해당 리스트에
rst 결과물을 추가(append)해주는 구조입니다.
이런 식으로 train/pos 경로의 모든 텍스트 파일들을
data['txt']라는 리스트에 추가할 수 있습니다.
하지만 지금 작업은 train의 pos 폴더 내용물에만 해당되는 것입니다.
아직 train_neg, test_pos, test_neg 폴더의 작업이 남아 있습니다 ㅜㅜ
3번의 작업을 반복해야 하니, 이 쯤에서 함수를 하나 만들어 주는 것이 좋을 듯 합니다.
def make_dict(dir):
data = {}
data['txt'] = []
for i in os.listdir(dir):
path = os.path.join(dir, i)
rst = open(path, "r", encoding="UTF-8").read()
data['txt'].append(rst)
return pd.DataFrame.from_dict(data)위와 같이 dir를 인자로 받는 함수를 하나 만들어 줬습니다.
리턴값은 판다스 데이터 프레임으로 지정해줬습니다.
이제 이 함수를 이용해 4개 경로의 데이터를 담아보도록 하겠습니다.
train_pos = make_dict(os.path.join(basic_dir, 'aclImdb', 'train', 'pos'))
train_neg = make_dict(os.path.join(basic_dir, 'aclImdb', 'train', 'neg'))
test_pos = make_dict(os.path.join(basic_dir, 'aclImdb', 'test', 'pos'))
test_neg = make_dict(os.path.join(basic_dir, 'aclImdb', 'test', 'neg'))이렇게 4개 변수에 만들어 준 함수를 적용하면, 각각 경로의 데이터를 모두 담을 수 있습니다.
이제 이 4개 데이터에 라벨링을 해주고, 데이터를 통합해주는 일만 남았습니다.
3. 데이터 라벨링하고 통합해주기
train_pos['label'] = 1
train_neg['label'] = 0
test_pos['label'] = 1
test_neg['label'] = 0라벨링을 해주는 코드입니다.
긍정적인 리뷰 데이터는 1 이라는 라벨을 달아주고,
부정적인 리뷰 데이터는 0 이라는 라벨을 달았습니다.
라벨링은 위와 같이 컴퓨터가 이해하기 쉽도록, 꼬리표(label)를 달아주는 작업입니다.
주로 머신러닝의 지도학습에 사용할 용도로 라벨링을 해줍니다.
train_data = pd.concat([train_pos, train_neg])
test_data = pd.concat([test_pos, test_neg])마지막으로 데이터를 통합해줍니다.
pd.concat 함수를 사용했습니다.
pd.concat은 데이터를 세로로 통합해주는 역할을 합니다.
행과 열이 있는 데이터에서, 열은 고정해두고 행을 통합한다는 의미입니다.
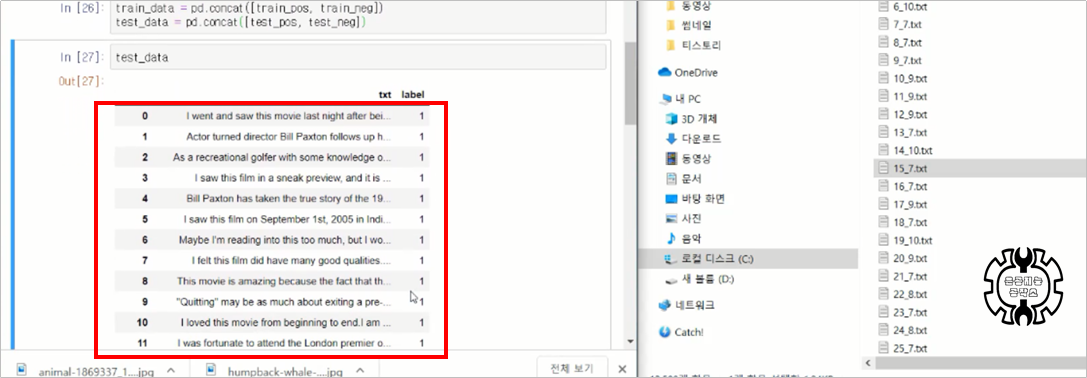
test_data를 출력해본 모습입니다.
1 라벨과 0 라벨이 모두 잘 달린 25,000개의 데이터를 확인하실 수 있습니다.
네 이렇게 오늘은 IMDb 영화데이터를 전처리하고 라벨링하는 작업까지 해보았습니다.
쓰고나니 너무 장황하게 설명해놓은 감이 있네요 ㅜㅜ
원래 제가 좀 TMI 기질이 다분히 있어서.. ㅋㅋ 모쪼록 긴 글 읽어주셔서 감사합니다.
반응형
'딥러닝 공부 > 자연어처리' 카테고리의 다른 글

pychan
딥러닝에 관련된 시행착오, 사소하지만 중요한 것들, 가능한 모든 여정을 담았습니다.