[Python/Tensorflow] tf.estimator error 해결 (Fetch 0 argument has invalid type error, TF_SessionRun_wrapper error)
딥러닝 공부/설치 및 환경설정 2019. 8. 30. 13:48
안녕하세요. 은공지능 공작소의 파이찬입니다.
오늘은 Tensorflow estimator의 2가지 에러를 해결하는 포스팅을 준비했습니다.
1. TypeError: Fetch argument 0 has invalid type <class 'numpy.int64'> must be string or Tensor
2. TypeError: TF_SessionRun_wrapper: expected all value in input dict to be ndarray
자신의 코드와 데이터에 문제가 없는데, 자꾸 위의 에러가 뜨시는 분들은
계속 포스팅을 봐주시길 바랍니다. 우선 간단한 요약부터 시작하겠습니다.
1. 트러블 슈팅 요약
pip uninstall numpy # numpy 없다고 뜰 때까지 계속 반복해주세요.
pip install numpy # 저는 1.17버전이 깔렸으니, 참고해주세요.
pip install cython # 이 부분은 스킵해도 될 수 있는데, 저는 실행하였기에 남겨둡니다.Tensorflow estimator에서 TypeError가 뜬 이유는 Numpy 라이브러리 때문이었습니다.
1.15 버전과 1.16 버전이 충돌해서 문제가 발생하는 것 같았습니다.
위의 코드처럼 numpy를 지웠다가 다시 깔아주면 문제는 해결됩니다.
만약 더 자세한 설명이 필요하신 분들은 계속 봐주세요.
2-1. 문제 상황 (에러 메시지)
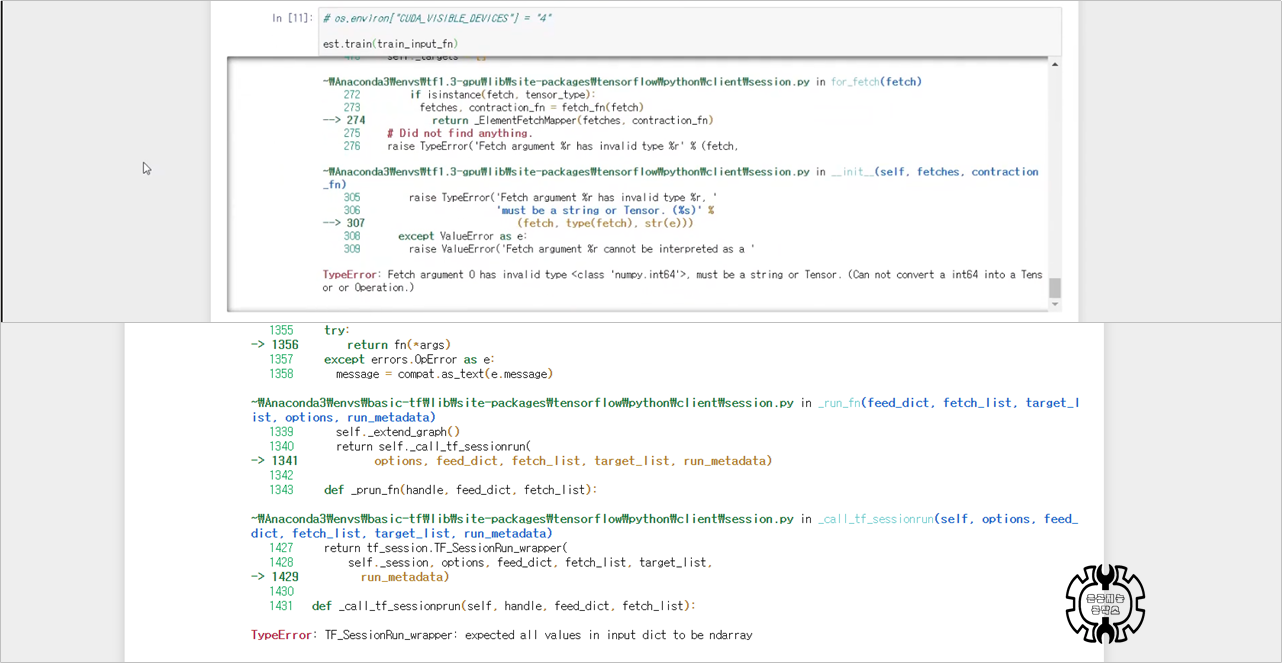
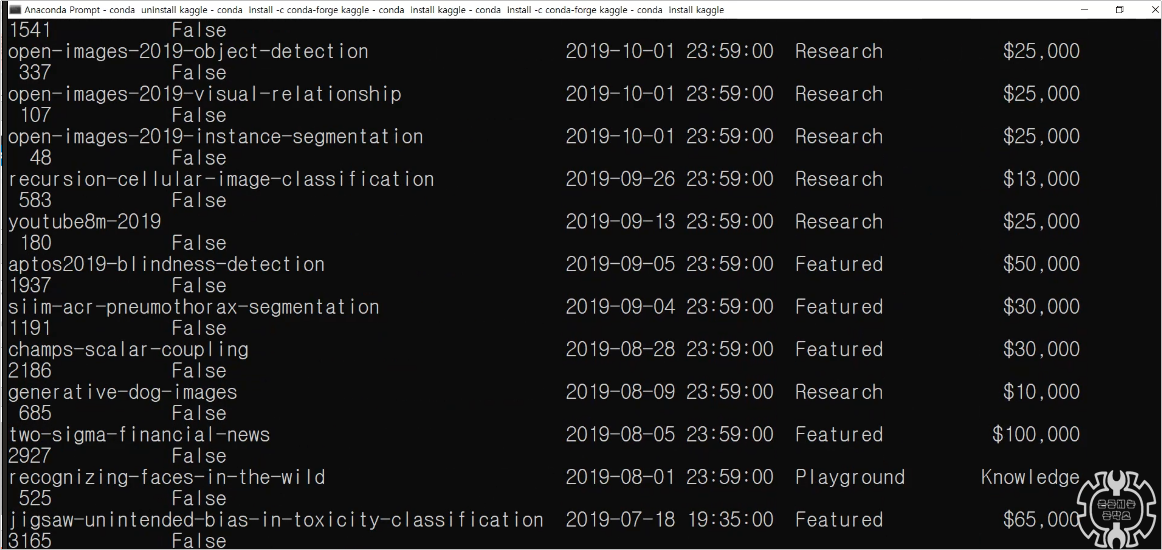
위와 같이 2가지 에러메시지가 뜨는 상황입니다.
각각 다른 코드인데, 해결법은 동일합니다.
2-2. 모든 프로그램 창 닫아주기 (주피터, 파이참 등)
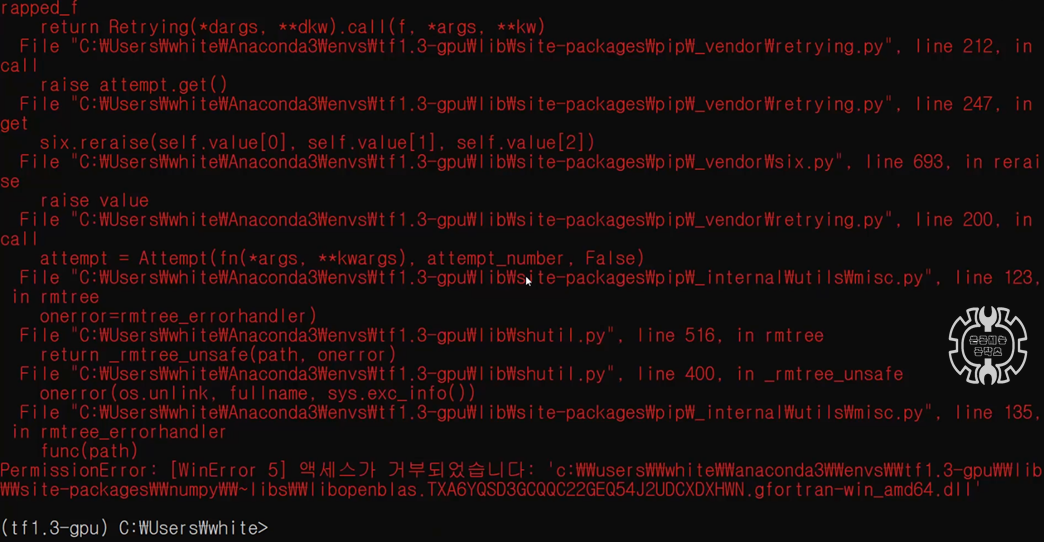
반드시 모든 프로그램(파이참, 주피터 등)을 닫아주시길 바랍니다.
안 그러면, 위와 같은 PermissionError 메시지가 뜹니다...
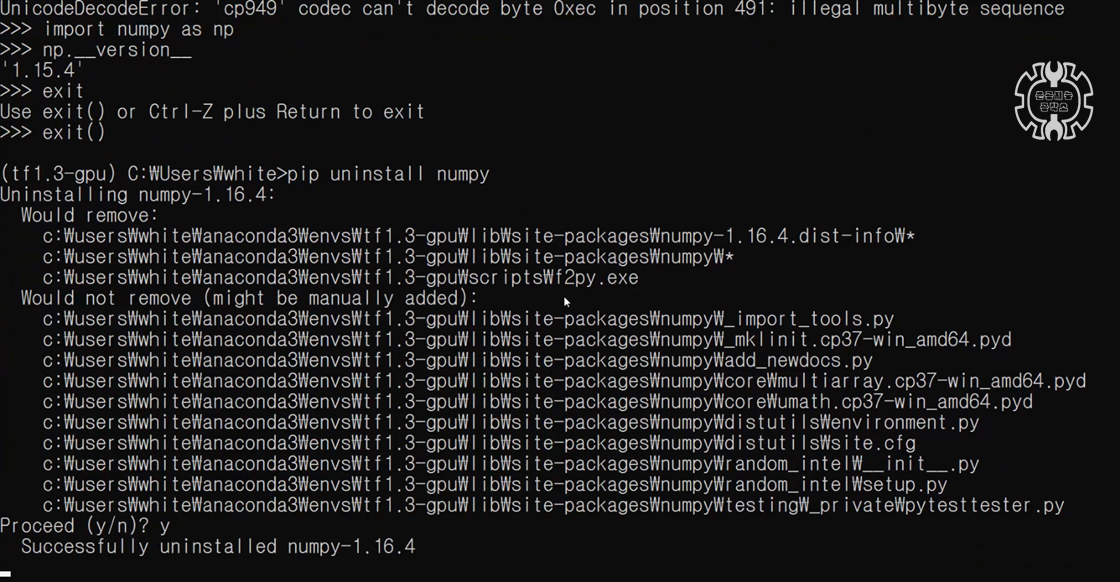
그래도 Numpy가 제거는 됩니다 ㅎㅎ
위의 사진은 주피터 노트북을 킨 상태에서 pip uninstall numpy를 날려줬을 때의 모습입니다.
마지막 줄에 numpy 1.16 버전이 제거가 되었다고 뜬 것을 확인하실 수 있을 겁니다.
그래도 여러분들은 저같은 시행착오를 방지하기 위해서,
꼭 모든 프로그램을 닫고 명령어를 날려주시길 바랍니다. 계속 진행해보겠습니다.
2-3. pip uninstall numpy 명령어 실행
(numpy가 없다고 뜰 때까지 계속 반복)
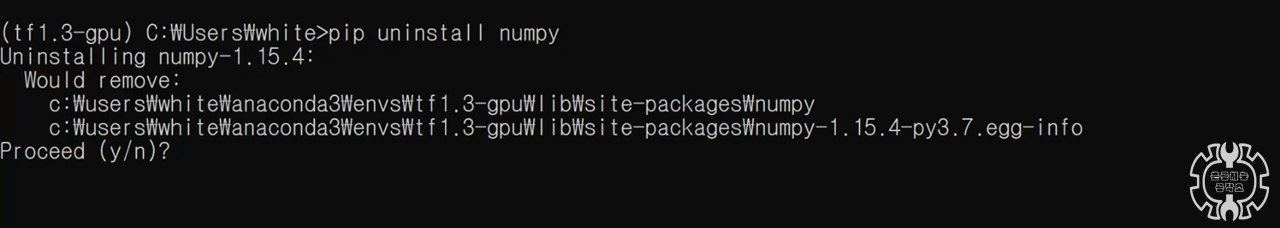
다시 모든 프로그램을 종료하고 돌아왔습니다.
그리고 pip uninstall numpy 명령어를 날려줍니다.
역시 제거할 numpy가 남아있었네요.
아까 분명 numpy 1.16 버전이 제거가 되었다고 된 상태였음에도, 1.15버전이 남아있습니다.
y를 눌러서 제거를 해주시면 됩니다.
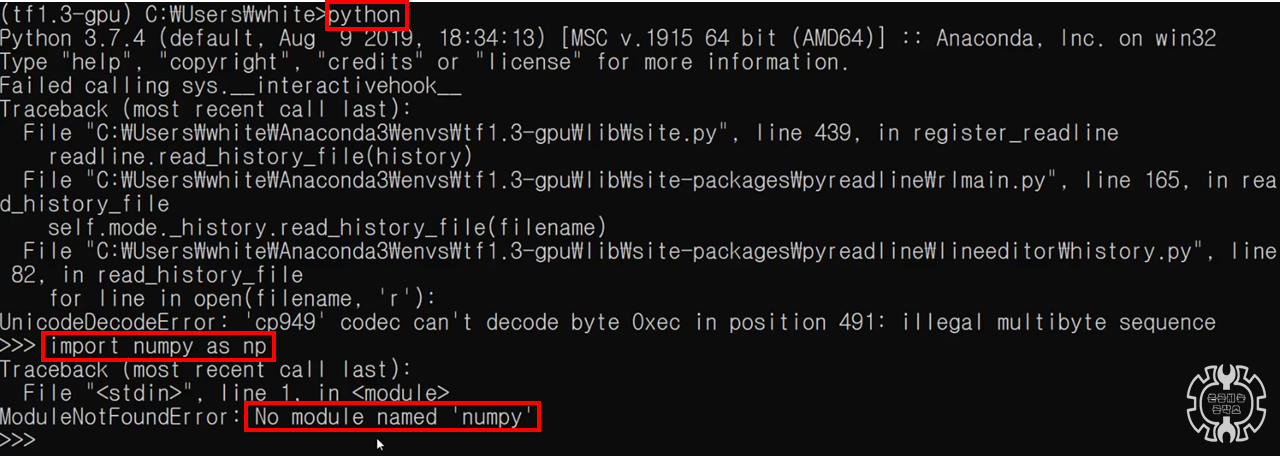
numpy가 깔끔하게 제거되었는지 알아보기 위해, 간단한 테스트를 진행해보겠습니다.
위의 화면처럼 우선 python을 실행시켜주시길 바랍니다. 그냥 python이라고 치시면 돼요 ㅎㅎ
파이썬이 실행이 되었다면, '>>>'이런 표시가 코드에 나타나게 됩니다.
이 상태에서 import numpy 명령어를 통해, numpy 라이브러리를 불러와줍니다.
No module named 'numpy'라고 뜬 부분이 보이시나요?
numpy라는 라이브러리가 성공적으로 제거가 되었다는 뜻입니다.
2-4. pip install numpy 명령어 실행
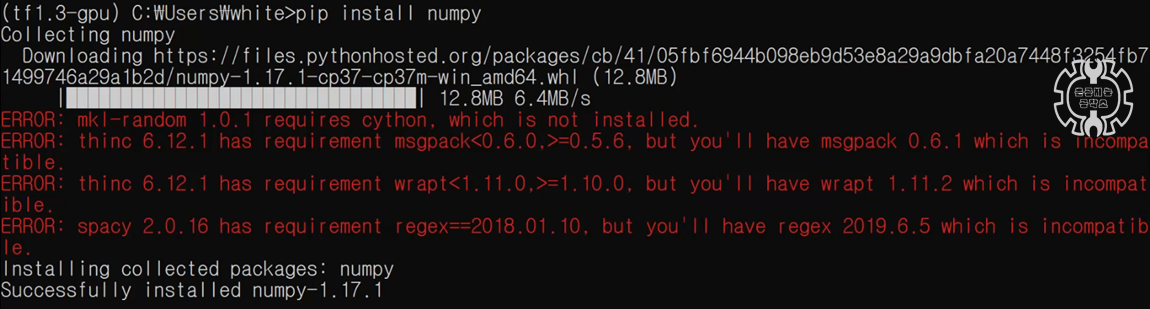
pip install numpy 명령어를 날려서, 다시 numpy를 설치해줍니다.
마지막줄을 보니, numpy 1.17.1 버전이 설치가 되었군요.
하지만 빨간색줄로 에러가 상당히 많이 떠서... 좀 거슬립니다.
그래서 cython만 우선 설치해보고 테스트를 해보기로 했습니다.

cython이 성공적으로 설치가 된 모습입니다.
이 부분은 스킵을 해도 상관 없을 것 같긴 합니다.
하지만 저는 실행시켜준 부분이기에, 혹시 몰라 이렇게 알려드리는 겁니다.
3. 코딩 테스트
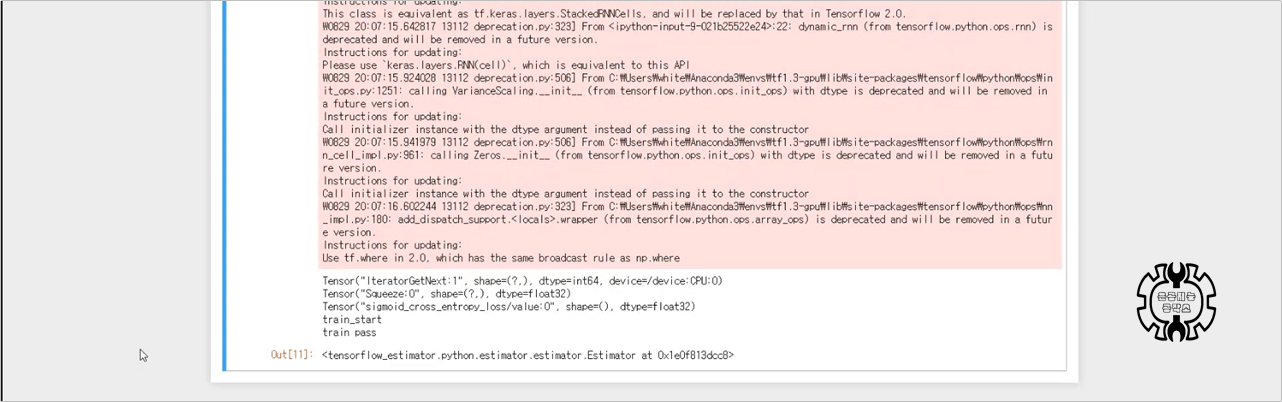
다시 코드를 돌려보니, 에러가 났던 것이 정상적으로 작동합니다.
이 에러를 가지고 거의 3일동안 씨름했거든요.. ㅜㅜ 감개무량합니다.

이렇게 오늘은 텐서플로우 에스티메이터 TypeError를 해결해보았습니다.
여름이 끝나가는데, 다들 여름휴가는 다녀오셨나요? ㅎㅎ
가끔은 머리도 식히고, 휴식도 필요하다는 것 잊지 마세요~!
지금까지 은공지능 공작소의 파이찬이었습니다.
감사합니다.
반응형
'딥러닝 공부 > 설치 및 환경설정' 카테고리의 다른 글
| [Jupyter] 주피터 노트북 초보자들을 위한 단축키 꿀팁 5가지 (2) | 2019.08.29 |
|---|---|
| [Anaconda/Python] Kaggle API로 데이터 다운받기 (4) | 2019.07.29 |
| [Anaconda/Python] Permission 에러 없는 Spacy 라이브러리 설치법 (0) | 2019.07.27 |
| [Python/Konlpy] JvmNotFoundException 에러 말끔하게 해결하기 (제대로 된 자바 설치법) (0) | 2019.07.27 |
| [Jupyter notebook] 초간단 ipynb 커널 바꾸는 방법 (1) | 2019.07.24 |

pychan
딥러닝에 관련된 시행착오, 사소하지만 중요한 것들, 가능한 모든 여정을 담았습니다.